Requests and BeautifulSoup
Ultimate Guide to Web Scraping with Python Part 1: Requests and BeautifulSoup
After the 2016 election I became much more interested in media bias and the manipulation of individuals through advertising. This series will be a walkthrough of a web scraping project that monitors political news from both left and right wing media outlets and performs an analysis on the rhetoric being used, the ads being displayed, and the sentiment of certain topics.
The first part of the series will we be getting media bias data and focus on only working locally on your computer, but if you wish to learn how to deploy something like this into production, feel free to leave a comment and let me know.
Limit your impact when scraping
Every time you load a web page you're making a request to a server, and when you're just a human with a browser there's not a lot of damage you can do. With a Python script that can execute thousands of requests a second if coded incorrectly, you could end up costing the website owner a lot of money and possibly bring down their site (see Denial-of-service attack (DoS)).
With this in mind, we want to be very careful with how we program scrapers to avoid crashing sites and causing damage. Every time we scrape a website we want to attempt to make only one request per page. We don't want to be making a request every time our parsing or other logic doesn't work out, so we need to parse only after we've saved the page locally.
If I'm just doing some quick tests, I'll usually start out in a Jupyter notebook because you can request a web page in one cell and have that web page available to every cell below it without making a new request. Since this article is available as a Jupyter notebook, you will see how it works if you choose that format.
How to save HTML locally
After we make a request and retrieve a web page's content, we can store that content locally with Python's open() function. To do so we need to use the argument wb, which stands for "write bytes". This let's us avoid any encoding issues when saving.
Below is a function that wraps the open() function to reduce a lot of repetitive coding later on:
def save_html(html, path):
with open(path, 'wb') as f:
f.write(html)
save_html(r.content, 'google_com')Assume we have captured the HTML from google.com in html, which you'll see later how to do. After running this function we will now have a file in the same directory as this notebook called google_com that contains the HTML.
How to open/read HTML from a local file
To retrieve our saved file we'll make another function to wrap reading the HTML back into html. We need to use rb for "read bytes" in this case.
The open function is doing just the opposite: read the HTML from google_com. If our script fails, notebook closes, computer shutsdown, etc., we no longer need to request google.com again, lessening our impact on their servers. While it doesn't matter much with Google since they have a lot of resources, smaller sites with smaller servers will benefit from this.
I save almost every page and parse later when web scraping as a safety precaution.
Follow the rules for scrapers and bots
Each site usually has a robots.txt on the root of their domain. This is where the website owner explicitly states what bots are allowed to do on their site. Simply go to example.com/robots.txt and you should find a text file that looks something like this:
The User-agent field is the name of the bot and the rules that follow are what the bot should follow. Some robots.txt will have many User-agents with different rules. Common bots are googlebot, bingbot, and applebot, all of which you can probably guess the purpose and origin of.
We don't really need to provide a User-agent when scraping, so User-agent: * is what we would follow. A * means that the following rules apply to all bots (that's us).
The Crawl-delay tells us the number of seconds to wait before requests, so in this example we need to wait 10 seconds before making another request.
Allow gives us specific URLs we're allowed to request with bots, and vice versa for Disallow.
In this example we're allowed to request anything in the /pages/ subfolder which means anything that starts with example.com/pages/. On the other hand, we are disallowed from scraping anything from the /scripts/ subfolder.
Many times you'll see a * next to Allow or Disallow which means you are either allowed or not allowed to scrape everything on the site.
Sometimes there will be a disallow all pages followed by allowed pages like this:
This means that you're not allowed to scrape anything except the subfolder /pages/. Essentially, you just want to read the rules in order where the next rule overrides the previous rule.
Scraping Project: Getting Media Bias Data
This project will primarily be run through a Jupyter notebook, which is done for teaching purposes and is not the usual way scrapers are programmed. After showing you the pieces, we'll put it all together into a Python script that can be run from command line or your IDE of choice.
Making web requests
With Python's requests library we're getting a web page by using get() on the URL. The response r contains many things, but using r.content will give us the HTML. Once we have the HTML we can then parse it for the data we're interested in analyzing.
There's an interesting website called AllSides that has a media bias rating table where users can agree or disagree with the rating.
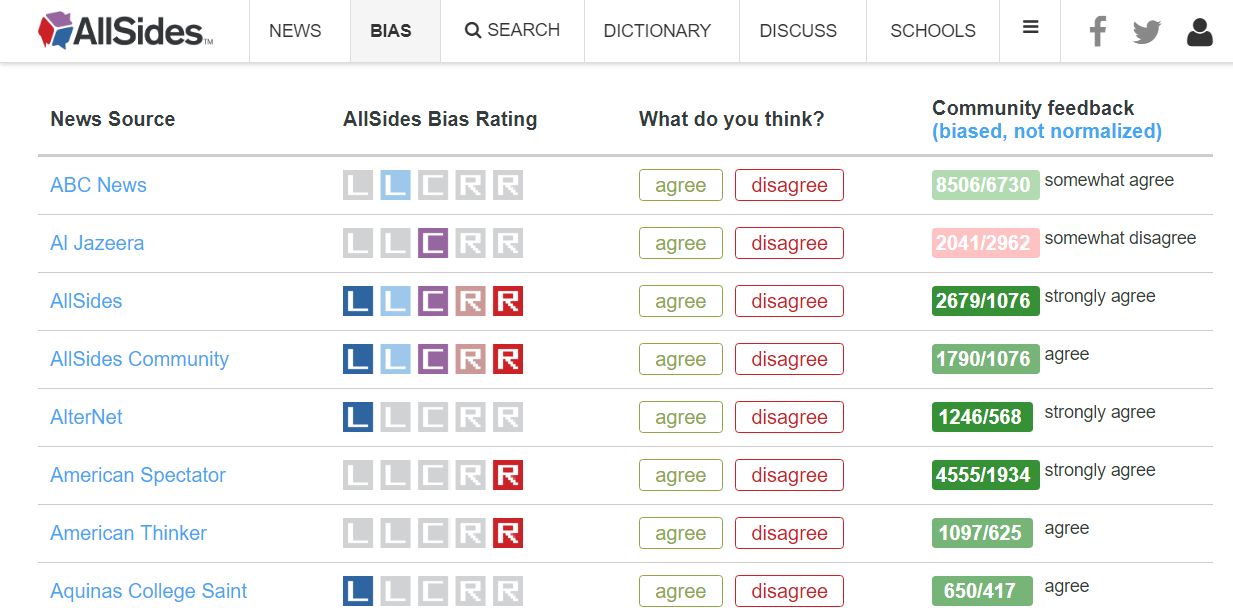
Since there's nothing in their robots.txt that disallows us from scraping this section of the site, I'm assuming it's okay to go ahead and extract this data for our project. Let's request the this first page:
Since we essentially have a giant string of HTML, we can print a slice of 100 characters to confirm we have the source of the page. Let's start extracting data.
Parsing HTML with BeautifulSoup
What does BeautifulSoup do?
We used requests to get the page from the AllSides server, but now we need the BeautifulSoup library to parse HTML and XML. When we pass our HTML to the BeautifulSoup constructor we get an object in return that we can then navigate like the original tree structure of the DOM.
This way we can find elements using names of tags, classes, IDs, and through relationships to other elements, like getting the children and siblings of elements.
Creating a new soup object
We create a new BeautifulSoup object by passing the constructor our newly acquired HTML content and the type of parser we want to use:
This soup object defines a bunch of methods — many of which can achieve the same result — that we can use to extract data from the HTML. Let's start with finding elements.
Finding elements and data
To find elements and data inside our HTML we'll be using select_one, which returns a single element, and select, which returns a list of elements (even if only one item exists). Both of these methods use CSS selectors to find elements, so if you're rusty on how CSS selectors work here's a quick refresher:
A CSS selector refresher
To get a tag, such as
<a></a>,<body></body>, use the naked name for the tag. E.g.select_one('a')gets an anchor/link element,select_one('body')gets the body element.tempgets an element with a class of temp, E.g. to get<a class="temp"></a>useselect_one('.temp')#tempgets an element with an id of temp, E.g. to get<a id="temp"></a>useselect_one('#temp').temp.examplegets an element with both classes temp and example, E.g. to get<a class="temp example"></a>useselect_one('.temp.example').temp agets an anchor element nested inside of a parent element with class temp, E.g. to get<div class="temp"><a></a></div>useselect_one('.temp a'). Note the space between.tempanda..temp .examplegets an element with class example nested inside of a parent element with class temp, E.g. to get<div class="temp"><a class="example"></a></div>useselect_one('.temp .example'). Again, note the space between.tempand.example. The space tells the selector that the class after the space is a child of the class before the space.ids, such as
<a id=one></a>, are unique so you can usually use the id selector by itself to get the right element. No need to do nested selectors when using ids.
There's many more selectors for for doing various tasks, like selecting certain child elements, specific links, etc., that you can look up when needed. The selectors above get us pretty close to everything we would need for now.
Tips on figuring out how to select certain elements
Most browsers have a quick way of finding the selector for an element using their developer tools. In Chrome, we can quickly find selectors for elements by
Right-click on the the element then select "Inspect" in the menu. Developer tools opens and and highlights the element we right-clicked
Right-click the code element in developer tools, hover over "Copy" in the menu, then click "Copy selector"
Sometimes it'll be a little off and we need to scan up a few elements to find the right one. Here's what it looks like to find the selector and Xpath, another type of selector, in Chrom e:
Let's start! Getting data out of a table
Our data is housed in a table on AllSides, and by inspecting the header element we can find the code that renders the table and rows. What we need to do is `select` all the rows from the table and then parse out the information from each row.
Simplifying the table's HTML, the structure looks like this (comments <!-- --> added by me):
So to get each row, we just select all <tr> inside <tbody>:
tbody tr tells the selector to extract all <tr> (table row) tags that are children of the <tbody> body tag. If there were more than one table on this page we would have to make a more specific selector, but since this is the only table, we're good to go.
Now we have a list of HTML table rows that each contain four cells:
News source name and link
Bias data
Agreement buttons
Community feedback data
Below is a breakdown of how to extract each one.
News source name
Let's look at the first cell:
The outlet name (ABC News) is the text of an anchor tag that's nested inside a <td> tag, which is a cell — or table data tag.
Getting the outlet name is pretty easy: just get the first row in rows and run a select_one off that object:
The only class we needed to use in this case was .source-title since .views-field looks to be just a class each row is given for styling and doesn't provide any uniqueness.
Notice that we didn't need to worry about selecting the anchor tag a that contains the text. When we use .text is gets all text in that element, and since "ABC News" is the only text, that's all we need to do. Bear in mind that using select or select_one will give you the whole element with the tags included, so we need .text to give us the text between the tags.
.strip() ensures all the whitespace surrounding the name is removed. This is a good thing to always do since many websites use whitespace as a way to visually pad the text inside elements.
You'll notice that we can run BeautifulSoup methods right off one of the rows. That's because the rows become their own BeautifulSoup objects when we make a select from another BeautifulSoup object. On the other hand, our name variable is no longer a BeautifulSoup object because we called .text.
News source page link
We also need the link to this news source's page on AllSides. If we look back at the HTML we'll see that in this case we do want to select the anchor in order to get the href that contains the link, so let's do that:
It is a relative path in the HTML, so we prepend the site's URL to make it a link we can request later.
Getting the link was a bit different than just selecting an element. We had to access an attribute (href) of the element, which is done using brackets, like how we would access a Python dictionary. This will be the same for other attributes of elements, like src in images and videos.
Bias rating
We can see that the rating is displayed as an image so how can we get the rating in words? Looking at the HTML notice the link that surrounds the image has the text we need:
We could also pull the alt attribute, but the link looks easier. Let's grab it:
Here we selected the anchor tag by using the class name and tag together: .views-field-field-bias-image is the class of the <td> and <a> is for the anchor nested inside.
After that we extract the href just like before, but now we only want the last part of the URL for the name of the bias so we split on slashes and get the last element of that split (left-center).
Community feedback data
The last thing to scrape is the agree/disagree ratio from the community feedback area. The HTML of this cell is pretty convoluted due to the styling, but here's the basic structure:
The numbers we want are located in two span elements in the last div. Both span elements have classes that are unique in this cell so we can use them to make the selection:
Using .text will return a string, so we need to convert them to integers in order to calculate the ratio.
Side note: If you've never seen this way of formatting print statements in Python, the f at the front allows us to insert variables right into the string using curly braces. The :.2f is a way to format floats to only show two decimals places.
If you look at the page in your browser you'll notice that they say how much the community is in agreement by using "somewhat agree", "strongly agree", etc. so how do we get that? If we try to select it:
It shows up as None because this element is rendered with Javascript and requests can't pull HTML rendered with Javascript. We'll be looking at how to get data rendered with JS in a later article, but since this is the only piece of information that's rendered this way we can manually recreate the text.
To find the JS files they're using, just CTRL+F for ".js" in the page source and open the files in a new tab to look for that logic.
It turned out the logic was located in the eleventh JS file and they have a function that calculates the text and color with these parameters:
Range
Agreeance
$ratio > 3$
absolutely agrees
$2
$1.5
$1
$ratio = 1$
neutral
$0.67
$0.5
$0.33
$ratio \leq 0.33$
absolutely disagrees
Let's make a function that replicates this logic:
Now that we have the general logic for a single row and we can generate the agreeance text, let's create a loop that gets data from every row on the first page:
In the loop we can combine any multi-step extractions into one to create the values in the least number of steps.
Our data list now contains a dictionary containing key information for every row.
Keep in mind that this is still only the first page. The list on AllSides is three pages long as of this writing, so we need to modify this loop to get the other pages.
Requesting and parsing multiple pages
Notice that the URLs for each page follow a pattern. The first page has no parameters on the URL, but the next pages do; specifically they attach a ?page=# to the URL where '#' is the page number.
Right now, the easiest way to get all pages is just to manually make a list of these three pages and loop over them. If we were working on a project with thousands of pages we might build a more automated way of constructing/finding the next URLs, but for now this works.
According to AllSides' robots.txt we need to make sure we wait ten seconds before each request.
Our loop will:
request a page
parse the page
wait ten seconds
repeat for next page.
Remember, we've already tested our parsing above on a page that was cached locally so we know it works. You'll want to make sure to do this before making a loop that performs requests to prevent having to reloop if you forgot to parse something.
By combining all the steps we've done up to this point and adding a loop over pages, here's how it looks:
Now we have a list of dictionaries for each row on all three pages.
To cap it off, we want to get the real URL to the news source, not just the link to their presence on AllSides. To do this, we will need to get the AllSides page and look for the link.
If we go to ABC News' page there's a row of external links to Facebook, Twitter, Wikipedia, and the ABC News website. The HTML for that sections looks like this:
Notice the anchor tag (<a>) that contains the link to ABC News has a class of "www". Pretty easy to get with what we've already learned:
So let's make another loop to request the AllSides page and get links for each news source. Unfortunately, some pages don't have a link in this grey bar to the news source, which brings up a good point: always account for elements to randomly not exist.
Up until now we've assumed elements exist in the tables we scraped, but it's always a good idea to program scrapers in way so they don't break when an element goes missing.
Using select_one or select will always return None or an empty list if nothing is found, so in this loop we'll check if we found the website element or not so it doesn't throw an Exception when trying to access the href attribute.
Finally, since there's 265 news source pages and the wait time between pages is 10 seconds, it's going to take ~44 minutes to do this. Instead of blindly not knowing our progress, let's use the tqdm library to give us a nice progress bar:
tqdm is a little weird at first, but essentially tqdm_notebook is just wrapping around our data list to produce a progress bar. We are still able to access each dictionary, d, just as we would normally. Note that tqdm_notebook is only for Jupyter notebooks. In regular editors you'll just import tqdm from tqdm and use tqdm instead.
Saving our data
So what do we have now? At this moment, data is a list of dictionaries, each of which contains all the data from the tables as well as the websites from each individual news source's page on AllSides.
The first thing we'll want to do now is save that data to a file so we don't have to make those requests again. We'll be storing the data as JSON since it's already in that form anyway:
To load it back in when you need it:
If you're not familiar with JSON, just quickly open allsides.json in an editor and see what it looks like. It should look almost exactly like what data looks like if we print it in Python: a list of dictionaries.
Brief Data Analysis
Before ending this article I think it would be worthwhile to actually see what's interesting about this data we just retrieved. So, let's answer a couple of questions.
Which ratings for outlets does the community absolutely agree on?
To find where the community absolutely agrees we can do a simple list comprehension that checks each dict for the agreeance text we want:
Using some string formatting we can make it look somewhat tabular. Interestingly, C-SPAN is the only center bias that the community absolutely agrees on. The others for left and right aren't that surprising.
Making analysis easier with Pandas
Which ratings for outlets does the community absolutely disagree on?
To make analysis a little easier, we can also load our JSON data into a Pandas DataFrame as well. This is easy with Pandas since they have a simple function for reading JSON into a DataFrame.
As an aside, if you've never used Pandas, Matplotlib, or any of the other data science libraries, I would definitely recommend checking out Jose Portilla's data science course for a great intro to these tools and many machine learning concepts.
Now to the DataFrame:
Now filter the DataFrame by "agreeance_text":
It looks like much of the community disagrees strongly with certain outlets being rated with a "center" bias.
Let's make a quick visualization of agreeance. Since there's too many news sources to plot so let's pull only those with the most votes. To do that, we can make a new column that counts the total votes and then sort by that value:
Visualizing the data
To make a bar plot we'll use Matplotlib with Seaborn's dark grid style:
As mentioned above, we have too many news outlets to plot comfortably, so just make a copy of the top 25 and place it in a new df2 variable:
With the top 25 news sources by amount of feedback, let's create a stacked bar chart where the number of agrees are stacked on top of the number of disagrees. This makes the total height of the bar the total amount of feedback.
Below, we first create a figure and axes, plot the agree bars, plot the disagree bars on top of the agrees using bottom, then set various text features:
For a slightly more complex version, let's make a subplot for each bias and plot the respective news sources.
This time we'll make a new copy of the original DataFrame beforehand since we can plot more news outlets now.
Instead of making one axes, we'll create a new one for each bias to make six total subplots:
Hopefully the comments help with how these plots were created. We're just looping through each unique bias and adding a subplot to the figure.
When interpreting these plots keep in mind that the y-axis has different scales for each subplot. Overall it's a nice way to see which outlets have a lot of votes and where the most disagreement is. This is what makes scraping so much fun!
Final words
We have the tools to make some fairly complex web scrapers now, but there's still the issue with Javascript rendering. This is something that deserves its own article, but for now we can do quite a lot.
There's also some project organization that needs to occur when making this into a more easily runnable program. We need to pull it out of this notebook and code in command-line arguments if we plan to run it often for updates.
These sorts of things will be addressed later when we build more complex scrapers, but feel free to let me know in the comments of anything in particular you're interested in learning about.
Last updated