Web Scraping ฉบับคนไม่รู้ด้านนี้เลยก็สามารถทำได้ by Botnoi student
ในบทความนี้ผมจะพูดถึงการทำ Web Scraping ซึ่งเป็นวิธีการดึงข้อมูลจาก web page ต่างๆ เพื่อนำไปใช้ประโยชน์ตามที่เราต้องการ โดยจะใช้ Library BeautifulSoup ใน Python ครับ
บทความที่ผมจะมาแชร์ในวันนี้เป็นบางส่วนใน Botnoi data science classroom เป็นคลาสที่เปิดสอนสำหรับคนที่สนใจด้าน Data Science ครับ ซึ่ง web scraping เกี่ยวข้องกับด้านงานด้าน data ได้อย่างไร และจำเป็นมากแค่ไหนที่จะต้องรู้ ?
ดังที่ทราบกันว่าแหล่งข้อมูล (Data source) ที่ใหญ่ที่สุดคือ internet นั้นเองแล้วเราจะเข้าถึงข้อมูลที่มีอยู่ในนั้นได้อย่างไรล่ะ ก็โดย web scraping นั้นไง ซึ่งจะทำการสกัดและดึงข้อมูลจากแหล่งข้อมูล (ในที่นี้คือเว็บไซต์) เพื่อนำข้อมูลออกมาใช้ ดังเช่นว่า data scientist สามาถสร้าง model เพื่อเทรนหุ้น จากการดึงข้อมูลข่าวจากเว็บข่าวทั่วไป หรือ data analyst ทำการดึงข้อมูลร้านอาหารที่เปิดใหม่ล่าสุดในเขตกรุงเทพและปริมณฑลใน Wongnai มาทำการวิเคราะห์เพื่อจะใช้ประโยชน์ในด้านธุรกิจเป็นการต่อไป ขึ้นอยู่กับว่าเราจะนำข้อมูลที่ได้มานั้นไปใช้อย่างไร ซึ่งการดึงข้อมูลนั้นไม่ยากเลยครับ เรามาลอง scrape website เพื่อดึงข้อมูลออกมาใช้กันในบทความนี้ครับSyncsort:
ETL (Extract, Transform and Load)
ก่อนอื่นเรามาทำความเข้าใจกับคำว่า web scraping กันก่อน web scraping นั้นเป็นการดึงข้อมูลจากหน้าเว็บ (web page) โดยวิเคราะห์จากลักษณะของภาษา HTML (Hyper Text Markup Language) ที่ใช้ในการแสดงผลบนอินเตอร์เน็ตในลักษณะของข้อความ รูปภาพ ต่างๆ โดยการจะดึงข้อมูลออกมาขั้นต้น เราควรที่จะเข้าใจข้อมูลพื้นฐานของ web ก่อน เพื่อทำให้รู้ว่าถ้าจะเราสนใจข้อมูลตรงนี้ในเว็บ เราต้องดูตรงจุดไหน จะได้ดึงข้อมูลนั้นออกมาครบถ้วนและถูกต้องครับ
เรามาทำความเข้าใจภาษา HTML เบื้องต้นกันก่อนแบบไม่ต้องเขียนกันครับ
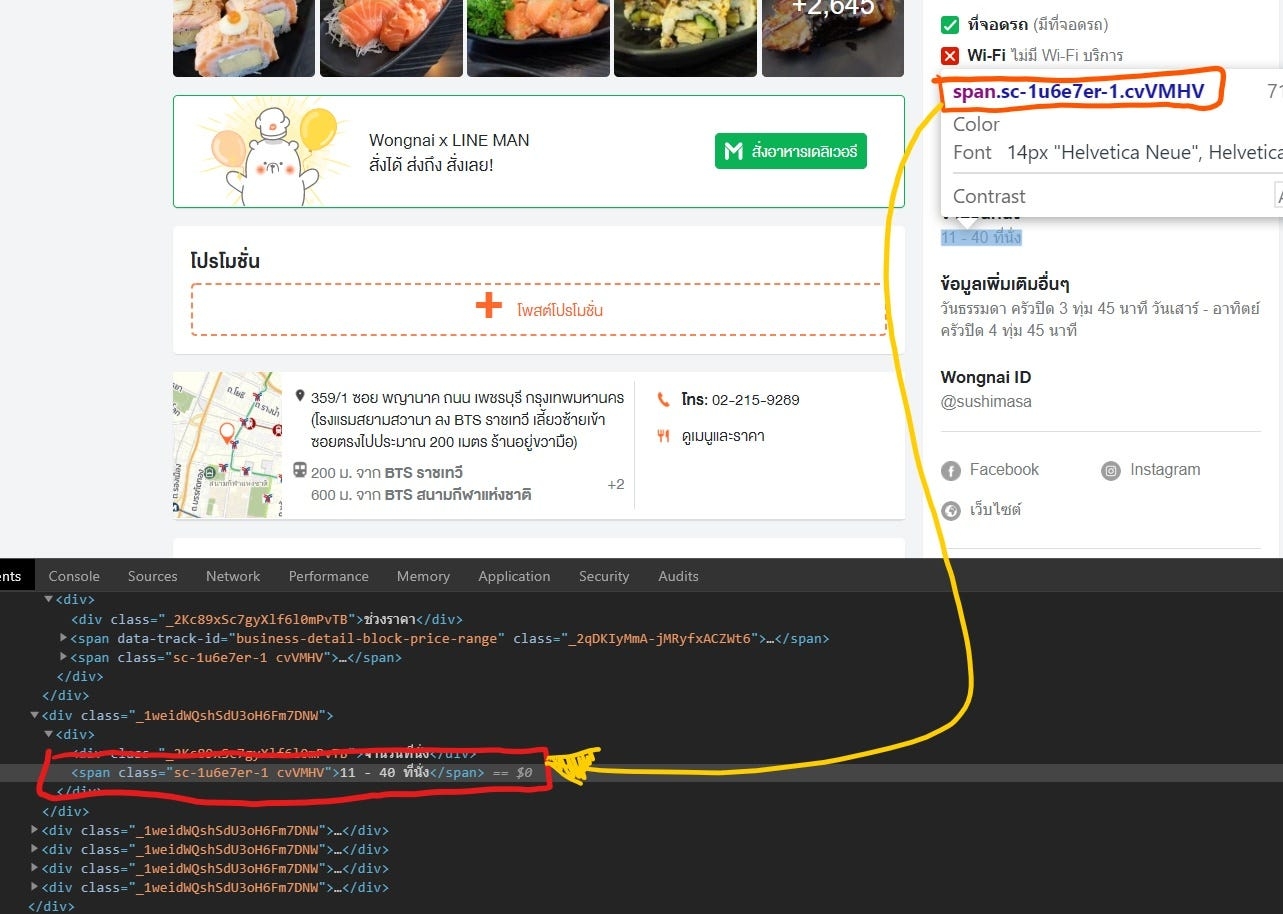
ภาพตัวอย่างหน้า HTML Page
โดยแต่ละส่วนประกอบหลักๆ จะมีชื่อเรียกดังนี้
Tag name ใช้ในการระบุรูปแบบคำสั่ง หรือการลงรหัสคำสั่ง ภายในเครื่องหมาย less-than bracket ( < ) และ greater-than bracket ( > ) โดยที่ Tag HTML แบ่งได้ 2 ลักษณะ คือ
Tag เดี่ยว เป็น Tag ที่ไม่ต้องมีการปิดรหัส เช่น <meta>, <link> เป็นต้น
Tag เปิด/ปิด รูปแบบของ tag นี้จะเป็นแบบ <title> …. </title> โดยที่ <title> เราเรียกว่า tag เปิด และ </title> เราเรียกว่า tag ปิด
ซึ่งเราจะใช้ tag เพื่อระบุตำแหน่งของข้อมูลที่ต้องการในการดึงข้อมูลออกมาครับ
Attribute คือ เป็นตัวบอกรายละเอียดของ tag นั้นเช่น <meta http-equiv=”Content type”> เป็นการบอกว่า meta นี้บรรจุ http อยู่ใน tag (http-equiv)
Value คือ ค่าของ Tag นั้น อย่างเช่น <meta http-equiv=”Content type”> มี Value คือ “Content-Type”
Nefted-element คือ Tag ย่อยที่ถูกบรรจุอยู่ อย่างในภาพ Tag ใหญ่ คือ <head>……</head> โดยมี Nefted-element คือ <meta> ,<title>…</title> และ <link>