Tools for Record Linking
Posted by Chris Moffitt in articles

Introduction
Record linking and fuzzy matching are terms used to describe the process of joining two data sets together that do not have a common unique identifier. Examples include trying to join files based on people’s names or merging data that only have organization’s name and address.
This problem is a common business challenge and difficult to solve in a systematic way - especially when the data sets are large. A naive approach using Excel and vlookup statements can work but requires a lot of human intervention. Fortunately, python provides two libraries that are useful for these types of problems and can support complex matching algorithms with a relatively simple API.
The first one is called fuzzymatcher and provides a simple interface to link two pandas DataFrames together using probabilistic record linkage. The second option is the appropriately named Python Record Linkage Toolkit which provides a robust set of tools to automate record linkage and perform data deduplication.
This article will discuss how to use these two tools to match two different data sets based on name and address information. In addition, the techniques used to do matching can be applied to data deduplication and will be briefly discussed.
The problem
Anyone that has tried to merge disparate data sets together has likely run across some variation of this challenge. In the simple example below, we have a customer record in our system and need to determine the data matches - without the use of a common identifier.

With a small sample set and our intuition, it looks like account 18763 is the same as account number A1278. We know that Brothers and Bro as well as Lane and LN are equivalent so this process is relatively easy for a person. However, trying to program logic to handle this is a challenge.
In my experience, most people start using excel to vlookup the various components of the address and try to find the best match based on the state, street number or zip code. In some cases, this can work. However there are more sophisticated ways to perform string comparisons that we might want to use. For example, I wrote briefly about a package called fuzzy wuzzy several years ago.
The challenge is that these algorithms (e.g. Levenshtein, Damerau-Levenshtein, Jaro-Winkler, q-gram, cosine) are computationally intensive. Trying to do a lot of matching on large data sets is not scaleable.
If you are interested in more mathematical details on these concepts, wikipedia is a good place to start and this article contains much more additional detail. Finally, this blog post discusses some of the string matching approaches in more detail.
Fortunately there are python tools that can help us implement these methods and solve some of these challenging problems.
The data
For this article, we will be using US hospital data. I chose this data set because hospital data has some unique qualities that make it challenging to match:
Many hospitals have similar names across different cities (Saint Lukes, Saint Mary, Community Hospital)
In urban areas, hospitals can occupy several city blocks so addresses can be ambiguous
Hospitals tend to have many clinics and other associated and related facilities nearby
Hospitals also get acquired and name changes are common - making this process even more difficult
Finally, there are a thousands of medical facilities in the US so the problem is challenging to scale
In these examples, I have two data sets. The first is an internal data set that contains basic hospital account number, name and ownership information.

The second data set contains hospital information (called provider) as well as the number of discharges and Medicare payment for a specific Heart Failure procedure.

The full data sets are available from Medicare.gov and CMS.gov and the simplified and cleaned version are available on github.
The business scenario is that we want to match up the hospital reimbursement information with our internal account data so we have more information to analyze our hospital customers. In this instance we have 5339 hospital accounts and 2697 hospitals with reimbursement information. Unfortunately we do not have a common ID to join on so we will see if we can use these python tools to merge the data together based on a combination of name and address information.
Approach 1 - fuzzymatcher
For the first approach, we will try using fuzzymatcher. This package leverages sqlite’s full text search capability to try to match records in two different DataFrames.
To install fuzzy matcher, I found it easier to conda install the dependencies (pandas, metaphone, fuzzywuzzy) then use pip to install fuzzymatcher. Given the computational burden of these algorithms you will want to use the compiled c components as much as possible and conda made that easiest for me.
If you wish to follow along, this notebook contains a summary of all the code.
After everything is setup, let’s import and get the data into our DataFrames:
Here is the hospital account information:
Here is the reimbursement information:
Since the columns have different names, we need to define which columns to match for the left and right DataFrames. In this case, our hospital account information will be the left DataFrame and the reimbursement info will be the right.
Now we let fuzzymatcher try to figure out the matches using fuzzy_left_join :
Behind the scenes, fuzzymatcher determines the best match for each combination. For this data set we are analyzing over 14 million combinations. On my laptop, this takes about 2 min and 11 seconds to run.
The matched_results DataFrame contains all the data linked together as well as as best_match_score which shows the quality of the link.
Here’s a subset of the columns rearranged in a more readable format for the top 5 best matches:

The first item has a match score of 3.09 and certainly looks like a clean match. You can see that the Facility Name and Provider Name for the Mayo Clinic in Red Wing has a slight difference but we were still able to get a good match.
We can check on the opposite end of the spectrum to see where the matches don’t look as good:
Which shows some poor scores as well as obvious mismatches:

This example highlights that part of the issue is that one set of data includes data from Puerto Rico and the other does not. This discrepancy highlights the need to make sure you really understand your data and what cleaning and filtering you may need to do before trying to match.
We’ve looked at the extreme cases, let’s take a look at some of the matches that might be a little more challenging by looking at scores < 80:

This example shows how some of the matches get a little more ambiguous. For example, is ADVENTIST HEALTH UKIAH VALLEY the same as UKIAH VALLEY MEDICAL CENTER? Depending on your data set and your needs, you will need to find the right balance of automated and manual match review.
Overall, fuzzymatcher is a useful tool to have for medium sized data sets. As you start to get to 10,000’s of rows, it will take a lot of time to compute, so plan accordingly. However the ease of use - especially when working with pandas makes it a great first place to start.
Approach 2 - Python Record Linkage Toolkit
The Python Record Linkage Toolkit provides another robust set of tools for linking data records and identifying duplicate records in your data.
The Python Record Linkage Toolkit has several additional capabilities:
Ability to define the types of matches for each column based on the column data types
Use “blocks” to limit the pool of potential matches
Provides ranking of the matches using a scoring algorithm
Multiple algorithms for measuring string similarity
Supervised and unsupervised learning approaches
Multiple data cleaning methods
The trade-off is that it is a little more complicated to wrangle the results in order to do further validation. However, the steps are relatively standard pandas commands so do not let that intimidate you.
For this example, make sure you install the library using pip . We will use the same data set but we will read in the data with an explicit index column. This makes subsequent data joins a little easier to interpret.
Because the Record Linkage Toolkit has more configuration options, we need to perform a couple of steps to define the linkage rules. The first step is to create a indexer object:
This WARNING points us to a difference between the record linkage library and fuzzymatcher. With record linkage, we have some flexibility to influence how many pairs are evaluated. By using full indexer all potential pairs are evaluated (which we know is over 14M pairs). I will come back to some of the other options in a moment. Let’s continue with the full index and see how it performs.
The next step is to build up all the potential candidates to check:
This quick check just confirmed the total number of comparisons.
Now that we have defined the left and right data sets and all the candidates, we can define how we want to perform the comparison logic using Compare()
We can define several options for how we want to compare the columns of data. In this specific example, we look for an exact match on the city. I have also shown some examples of string comparison along with the threshold and algorithm to use for comparison. In addition to these options, you can define your own or use numeric, dates and geographic coordinates. Refer to the documentation for more examples.
The final step is to perform all the feature comparisons using compute . In this example, using the full index, this takes 3 min and 41 s.
Let’s go back and look at alternatives to speed this up. One key concept is that we can use blocking to limit the number of comparisons. For instance, we know that it is very likely that we only want to compare hospitals that are in the same state. We can use this knowledge to setup a block on the state columns:
With the block on state, the candidates will be filtered to only include those where the state values are the same. We have filtered down the candidates to only 475,830. If we run the same comparison code, it only takes 7 seconds. A nice speedup!
In this data set, the state data is clean but if it were a little messier, we could use another the blocking algorithm like SortedNeighborhood to add some flexibility for minor spelling mistakes.
For instance, what if the state names contained “Tenessee” and “Tennessee”? Using blocking would fail but sorted neighborhood would handle this situation more gracefully.
In this case, sorted neighbors takes 15.9 seconds on 998,860 candidates which seems like a reasonable trade-off.
Regardless of which option you use, the result is a features DataFrame that looks like this:

This DataFrame shows the results of all of the comparisons. There is one row for each row in the account and reimbursement DataFrames. The columns correspond to the comparisons we defined. A 1 is a match and 0 is not.
Given the large number of records with no matches, it is a little hard to see how many matches we might have. We can sum up the individual scores to see about the quality of the matches.
Now we know that there are 988,187 rows with no matching values whatsoever. 7937 rows have at least one match, 451 have 2 and 2285 have 3 matches.
To make the rest of the analysis easier, let’s get all the records with 2 or 3 matches and add a total score:

Here is how to interpret the table. For the first row, Account_Num 26270 and Provider_Num 868740 match on city, hospital name and hospital address.
Let’s look at these two and see how close they are:
Yep. Those look like good matches.
Now that we know the matches, we need to wrangle the data to make it easier to review all the data together. I am going to make a concatenated name and address lookup for each of these source DataFrames.
Now merge in with the account data:

Finally, merge in the reimbursement data:
Let’s see what the final data looks like:

One of the differences between the toolkit approach and fuzzymatcher is that we are including multiple matches. For instance, account number 32725 could match two providers:

In this case, someone will need to investigate and figure out which match is the best. Fortunately it is easy to save all the data to Excel and do more analysis:
As you can see from this example, the Record Linkage Toolkit allows a lot more flexibility and customization than fuzzymatcher. The downside is that there is a little more manipulation to get the data stitched back together in order to hand the data over to a person to complete the comparison.
Deduplicating data with Record Linkage Toolkit

One of the additional uses of the Record Linkage Toolkit is for finding duplicate records in a data set. The process is very similar to matching except you pass match a single DataFrame against itself.
Let’s walk through an example using a similar data set:
Then create our indexer with a sorted neighbor block on State .
We should check for duplicates based on city, name and address:
Because we are only comparing with a single DataFrame, the resulting DataFrame has an Account_Num_1 and Account_Num_2 :

Here is how we score:
Add the score column:
Here’s a sample:
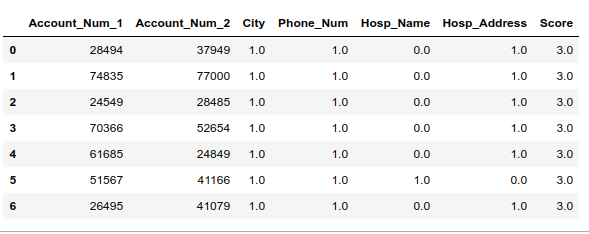
These 9 records have a high likelihood of being duplicated. Let’s look at an example to see if they might be dupes:
Yes. That looks like a potential duplicate. The name and address are similar and the phone number is off by one digit. How many hospitals do they really need to treat all those Packer fans? :)
As you can see, this method can be a powerful and relatively easy tool to inspect your data and check for duplicate records.
Advanced Usage
In addition to the matching approaches shown here, the Record Linkage Toolkit contains several machine learning approaches to matching records. I encourage interested readers to review the documentation for examples.
One of the pretty handy capabilities is that there is a browser based tool that you can use to generate record pairs for the machine learning algorithms.
Both tools include some capability for pre-processing the data to make the matching more reliable. Here is the preprocessing content in the Record Linkage Toolkit. This example data was pretty clean so you will likely need to explore some of these capabilities for your own data.
Summary
Linking different record sets on text fields like names and addresses is a common but challenging data problem. The python ecosystem contains two useful libraries that can take data sets and use multiple algorithms to try to match them together.
Fuzzymatcher uses sqlite’s full text search to simply match two pandas DataFrames together using probabilistic record linkage. If you have a larger data set or need to use more complex matching logic, then the Python Record Linkage Toolkit is a very powerful set of tools for joining data and removing duplicates.
Part of my motivation for writing this long article is that there are lots of commercial options out there for these problems and I wanted to raise awareness about these python options. Before you engage with an expensive consultant or try to pay for solution, you should spend an afternoon with these two options and see if it helps you out. All of the relevant code examples to get you started are in this notebook.
I always like to hear if you find these topics useful and applicable to your own needs. Feel free to comment below and let me know if you use these or any other similar tools.
credits: Title image - Un compositeur à sa casse
Reference : https://pbpython.com/record-linking.html
Last updated